Post
Multi-Variate, Multi-Step, LSTM for Anomaly Detection
This post will walk through a synthetic example illustrating one way to use a multi-variate, multi-step LSTM for anomaly detection.
Imagine you have a matrix of k time series data coming at you at regular intervals and you look at the last n observations for each metric.

A matrix of 5 metrics from period t to t-n
One approach to doing anomaly detection in such a setting is to build a model to predict each metric over each time step in your forecast horizon and when you notice your prediction errors start to change significantly this can be a sign of some anomalies in your incoming data.
This is essentially an unsupervised problem that can be converted into a supervised one. You train the model to predict its own training data. Then once it gets good at this (assuming your training data is relatively typical of normal behavior of your data), if you see some new data for which your prediction error is much higher then expected, that can be a sign that you new data is anomalous in some way.
Note: This example is adapted and built off of this tutorial which i found a very useful starting point. All the code for this post is in this notebook. The rest of this post will essentially walk though the code.
Imports & Paramaters
Below shows the imports and all the parameters for this example, you should be able to play with them and see what different results you get.
Note: There is a Pipfile here that shows the Python libraries needed. If you are not familiar, you should really check out pipenv, its really useful once you play with it a bit.
https://gist.github.com/andrewm4894/4540e23d86fa02859191a38998661849#file-keras_lstm_multi_imports_and_params-py
Fake Data!
We will generate some random data, and then smooth it out to look realistic. This will be our ‘normal’ data that we will use to train the model.

I couldn’t help myself.
Then we will make a copy of this normal data and inject in some random noise at a certain point and for a period of time. This will be our ‘broken’ data.
So this ‘broken’ data is the data that we should see the model struggle with in terms of prediction error. It’s this error (aggregated and summarized in some way, e.g. turned into a z-score) that you could then use to drive an anomaly score (you could also use loss from the continually re-training on new data whereby the training loss should initially spike once the broken data comes into the system but over time the training would then adapt the model to the new data).
https://gist.github.com/andrewm4894/417f54744ccf1e8a909c9e373abd21fd#file-keras_lstm_multi_generate_fake_data_normal-py
This gives us our normal-ish real word looking data that we will use to train the model.
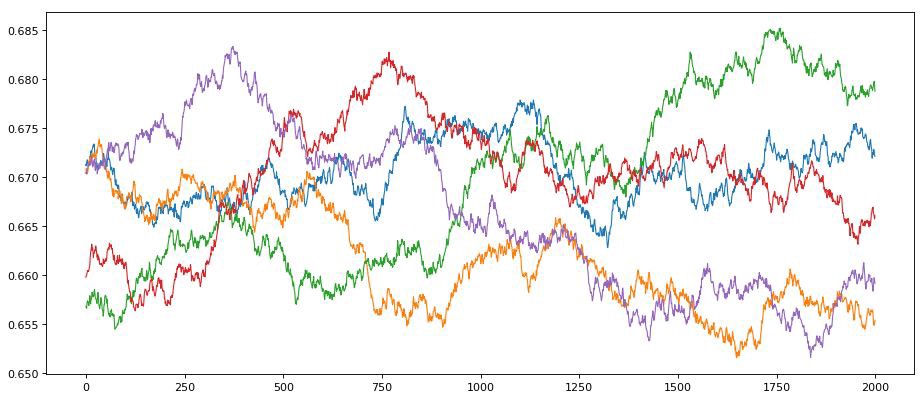
5 random time series that have been smoothed a bit to look realistic.
To make our ‘broken’ data (called data_new in the code) i lazily just copy the ‘normal’ data but mess up a segment of it with some random noise.
https://gist.github.com/andrewm4894/62174bbf299ecb36cada254314290644#file-keras_lstm_multi_generate_fake_data_broken-py
And so below we can see our ‘broken’ data. I’ve set the broken segment to be quite wide here and its very obvious the broken data is totally different. The hope is that in reality the model once trained would be good at picking up much more nuanced changes in the data that are less obvious to the human eye.
For example if all metrics were to suddenly become more or less correlated than normal but all still each move by a typical amount individually then this is the sort of change you’d like the model to highlight (this is probably something i should have tried to do when making the ‘broken’ data to make the whole example more realistic, feel free to try this yourself and let me know how you get on).
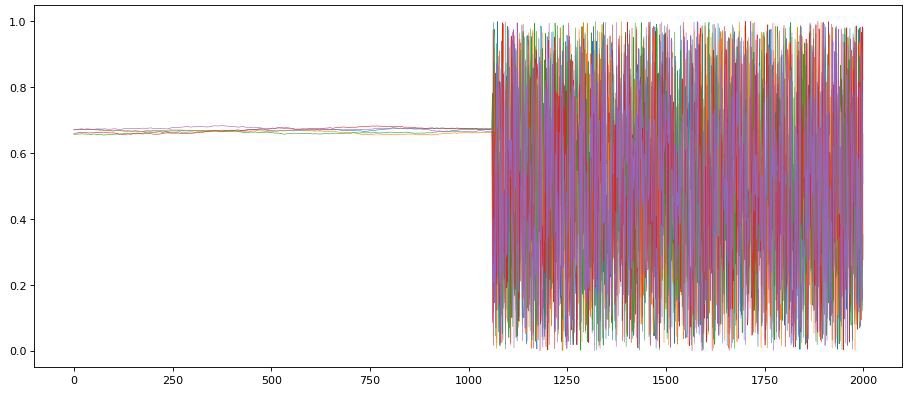
Same as the “normal” data but i’ve messed up a huge chunk of it.
Some Helper Functions
I’ve built some helper functions to make life easier in the example notebook. I’ll share the code below and talk a little about each.
- data_reshape_for_model() : This function basically takes in an typical dataframe type array, loops through that data and reshapes it all into a numpy array of the shape expected by the keras LSTM model for both training and prediction. Figuring out how to reshape the data based on the N_TIMESTEPS, N_FEATURES and length of the data was actually probably the trickiest part of this whole example. I’ve noticed that many tutorials online just reshape the data but do so in an incomplete way by essentially just pairing off rows. But what you really want to do is step through all the rows to make sure you roll your N_TIMESTEPS window properly over the data to as to all possible windows in your training.
- train() : This is just a simple wrapper for the keras train function. There is no real need for it.
- predict() : Similar to train() is just a wrapper function that does not really do much.
- model_data_to_df_long() : This function takes in a data array as used by the keras model and unrolls it into one big long pandas dataframe (numpy arrays freak me out a bit sometimes so i always try fall back pandas when i can get away with it 😉).
- model_df_long_to_wide() : This function then takes the long format dataframe created by model_data_to_df_long() and converts it into a wide format that is closed to the original dataset of one row one observation and one column for each input feature (plus lots more columns for predictions for each feature for each timestep).
- df_out_add_errors() : This function adds errors and error aggregation columns to the main df_out dataframe which stores all the predictions and errors for each original row of data.
- yhat_to_df_out() : This function take’s in the model formatted training data and model formatted prediction outputs and wraps all the above functions to make a nice little “df_out” dataframe that has everything we want in it and is one row one observation so lines up more naturally with the original data.
https://gist.github.com/andrewm4894/58179c6e240163a45dc2acff1843f7f2#file-keras_lstm_multi_helper_functions-py
Build & Train The Model
Below code builds the model, trains it and also calls predict on all the training data be able to get errors on the original ‘normal’ training data.
https://gist.github.com/andrewm4894/48fa72cf730eead43f3ce54cdb3842cb#file-keras_lstm_multi_build_and_train-py
We then call our “do everything” yhat_to_df_out() function on the training data and the predictions from the model.
https://gist.github.com/andrewm4894/9b8c108661fc640325f6be774a0a1861#file-keras_lstm_multi_make_df_out-py
Now we can plot lots of things from df_out. For example here are the errors averaged across all five features are each timestep prediction horizon.
https://gist.github.com/andrewm4894/50bf96cc87ac37079c55516f4068a4b6#file-keras_lstm_multi_plot_error_avg-py
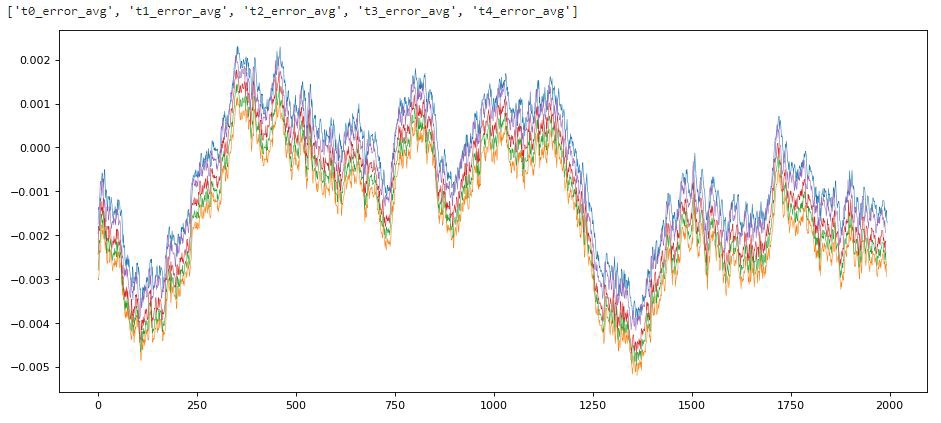
In the above plot we can see the averaged error of the model on its training data. Each line represents a different forecast horizon. We can see that the lines are sort of ‘stacked’ on top of each other which makes sense as you’d generally expect the error 5 timesteps out (red line “t4_error_avg”) to be higher then the one step ahead forecast (greeny/orangy line “t0_error_avg”).
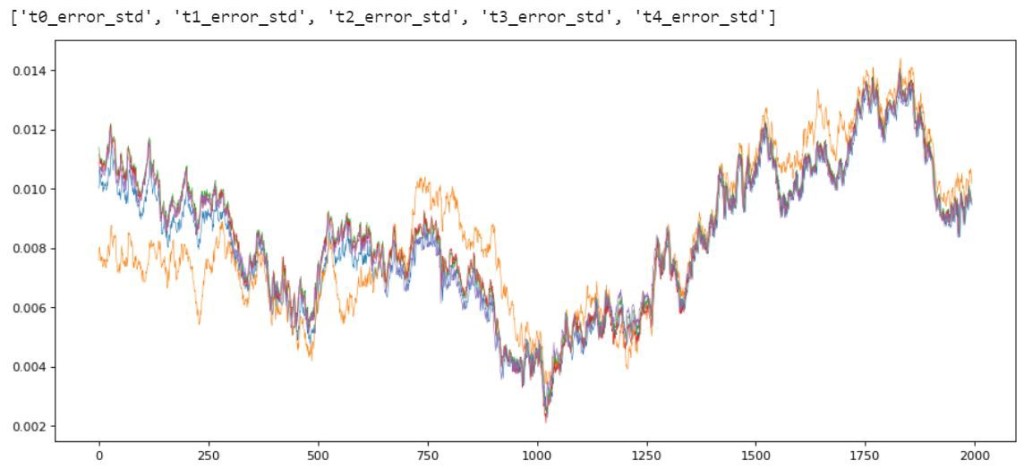
If we look at the standard deviation of our errors in a similar way, we can see how the standard deviation of our errors generally tends to increase at times when our 5 original features are diverging from each other as you can imagine these are the hardest parts of our time series for this model to predict.
Lets Break It
So now that we have our model trained on our ‘normal’ data we can use it to see how well it does at predicting our new ‘broken’ data.
https://gist.github.com/andrewm4894/fdb8ac2b8e8624e2a13e84b399f0faa1#file-keras_lstm_multi_build_and_train_new_broken_data-py
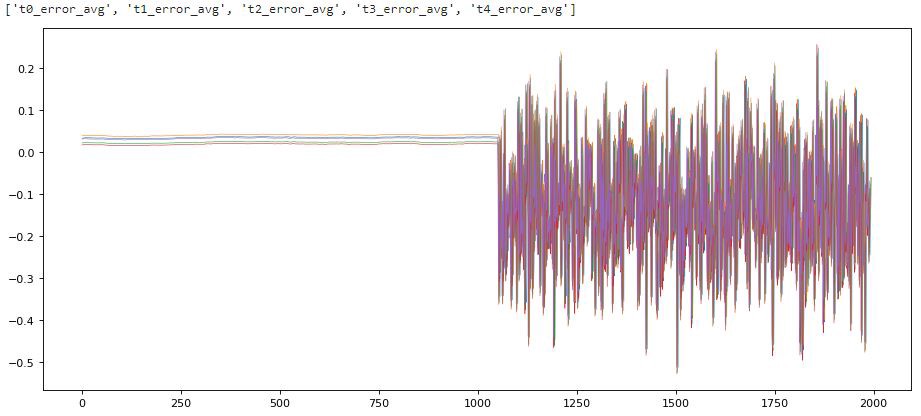
Here we can see that as soon as we hit the broken data the prediction errors go through the roof.
From the above we can see that as soon as the random broken data comes into the time series the model prediction errors explode.
As mentioned, this is a very obvious and synthetic use case just for learning on but the main idea is that if your data changed in a more complicated and harder to spot way then your error rates would everywhere reflect this change. These error rates could then be used as input into a more global anomaly score for your system.
That’s it, thanks for reading and feel free to add any comments or questions below. I may add some more complicated or real world examples building on this approach at a later stage.
UPDATE: Here is a Google Colab notebook that’s a bit better as i’ve worked a bit more on this since the original blog post.
Comments