Post
Some asyncio fun/pain
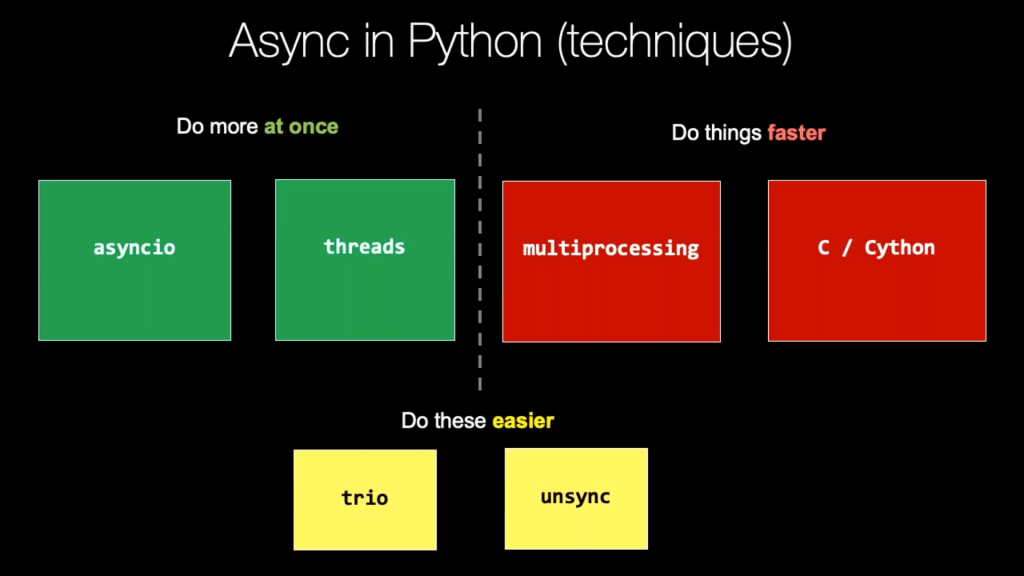
Taken from this great Talk Python Training course - get the lifetime bundle if you can!
You have a list of api endpoints you want to pull data from and collect results into some results list or dataframe for further processing. You could just loop over that list and make a load of requests.get() calls right. But no, you are a sexy ML engineer, this is a great excuse to spend half a day fumbling around the internet learning just enough asyncio to be dangerous!
I feel this is generalizable enough to merit a quick write up, and is the second time in last year that i have ‘solved’ this problem for myself so that ticks my boxes for a blog post, if only to help my future self.
On a work project, i have a list of about 200 api endpoints, all returning similar json data, that i want to combine and further wrangle. I tried a quick script to just iterate through all these requests but this was embarrassingly slow and given i want to share this script with some colleagues i decided to try virtue signal a little and use asyncio and in the process got the execution time from about 2 minutes to about 20 seconds which is very meaningful for me given this script is to be run a lot and iteratively as part of exploring a new feature i am working on.
Note: one important constraint is that this needs to be in base libraries in Python 3 (well ignoring requests :) ) so the the people i share this with only need to have Python 3. Otherwise i would probably use trio.
To be specific and make this example something anyone can run here is the setup. I have a monitoring dashboard/agent on a server - here is a demo server https://london.my-netdata.io.
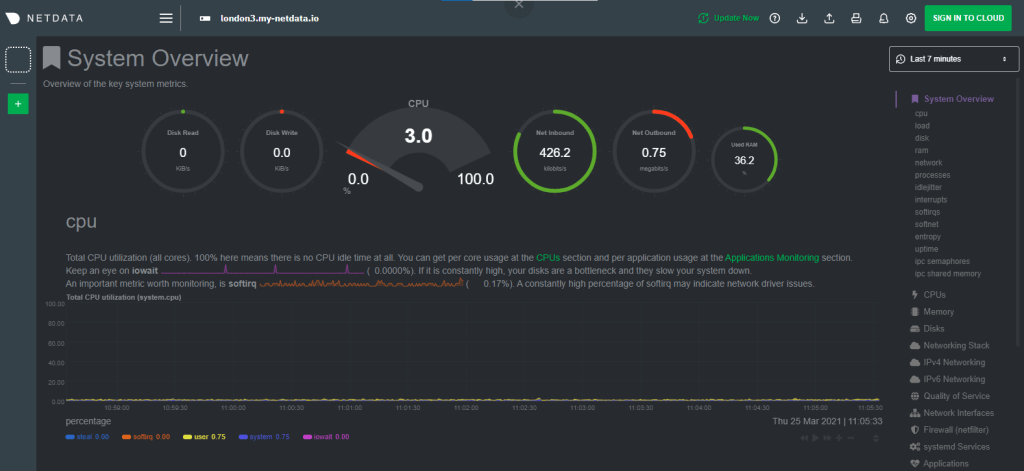
Example Netdata dashboard that also has a rest api for each chart available.
Now on this agent i have also a rest api endpoint for each chart so i can get the data if i want. For example here is an api call to get the recent data for the “system.cpu” chart (click it, go on): https://london.my-netdata.io/api/v1/data?chart=system.cpu.
What i want to do is have a script where you can just copy the url from the dashboard pass it as a parameter to a python script and then have that script go and pull all the charts (available here: https://london.my-netdata.io/api/v1/charts), average all the data for each chart and then just rank those charts based on that average value.
So some fairly simple processing of the data, bunch of urls, all have similar json data, process each in some way, and collect all the results into a list to then further process.
After a bit too much googling and attempts at reading the asyncio docs (which honestly just scared the bejesus out of me) here is a solution i managed to fumble my way to that actually works and is _good enough_tm for what i need so i stopped there.
Another note: since i’m feeling fancy, here is a Google colab notebook (assuming they have not killed colab by the time you read this - fingers crossed :) ) that will generate the script as a file and then run it. So feel free to go in there and click stuff.
#!/usr/bin/env python3
"""
Description:
Python script to take a url you can copy from a netdata dashboard, parse it and rank all charts based on the average of all their metrics and then print
out the top_n of that ranked list of charts along with a link to each chart.
Example Usage:
python process_charts.py --url="https://london.my-netdata.io"
"""
import requests
import asyncio
from urllib.parse import urlparse
import argparse
def request_sync(job):
"""Given a job, which is everything you need to make your api request,
kick off the api call and process the data a little.
"""
chart = job[0]
url = job[1]
print(f'getting data from {url}')
r = requests.get(url)
data = r.json()['data']
score = 0
if len(data) > 0:
# some charts might fail and that's ok :)
try:
data = [sum(d[1:]) / (len(d) - 1) for d in data]
score = round(sum(data)/len(data), 2)
except:
pass
return chart, score
async def request_async(job):
"""Wrap the requests.get() job in an asyncio loop.
"""
loop = asyncio.get_event_loop()
return await loop.run_in_executor(None, request_sync, job)
async def main(jobs):
"""Kick off all the jobs from a list of jobs, await and gather results.
"""
coroutines = [request_async(job) for job in jobs]
results = await asyncio.gather(*coroutines)
return results
if __name__ == "__main__":
# handle args
parser = argparse.ArgumentParser(description='Process charts.')
parser.add_argument('--url', help='url from netdata dashboard',
default='http://london.my-netdata.io/')
parser.add_argument('--n', help='top n charts by score', default=20)
args = parser.parse_args()
url = args.url
top_n = int(args.n)
# parse url
print(f'url is : {url}')
http = url.split('://')[0]
url_parsed = urlparse(url)
# get params from url
host = url_parsed.netloc
fragments = {x[0]: x[1] for x in [x.split('=') for x in url_parsed.fragment.split(';') if '=' in x]}
after = int(int(fragments['after']) / 1000) if 'after' in fragments else -600
before = int(int(fragments['before']) / 1000) if 'before' in fragments else 0
# get charts available
charts = requests.get(f'{http}://{host}/api/v1/charts').json()['charts']
charts_href = {
chart: f"#menu_{charts[chart]['type'].replace('.', '_')}_submenu_{charts[chart]['family'].replace('.', '_')}"
for chart in charts
}
# get scores via asyncio event loop
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
jobs = [(c, f'http://{host}/api/v1/data?chart={c}&points=5&after={after}&before={before}') for c in charts]
scores = loop.run_until_complete(main(jobs))
# create sorted dict from scores
scores = dict(sorted({r[0]: r[1] for r in scores}.items(), key=lambda item: item[1], reverse=True))
# print top n
print('--' * 20)
print(f'top {top_n} charts')
print('--' * 20)
for i, chart in enumerate(list(scores.keys())[0:top_n]):
print(str(i + 1).ljust(3), chart.ljust(40), format(scores[chart], '.2f'),
f'link = {http}://{host}/{charts_href[chart]};after={after * 1000};before={before * 1000}')
This should run and give you something like this:
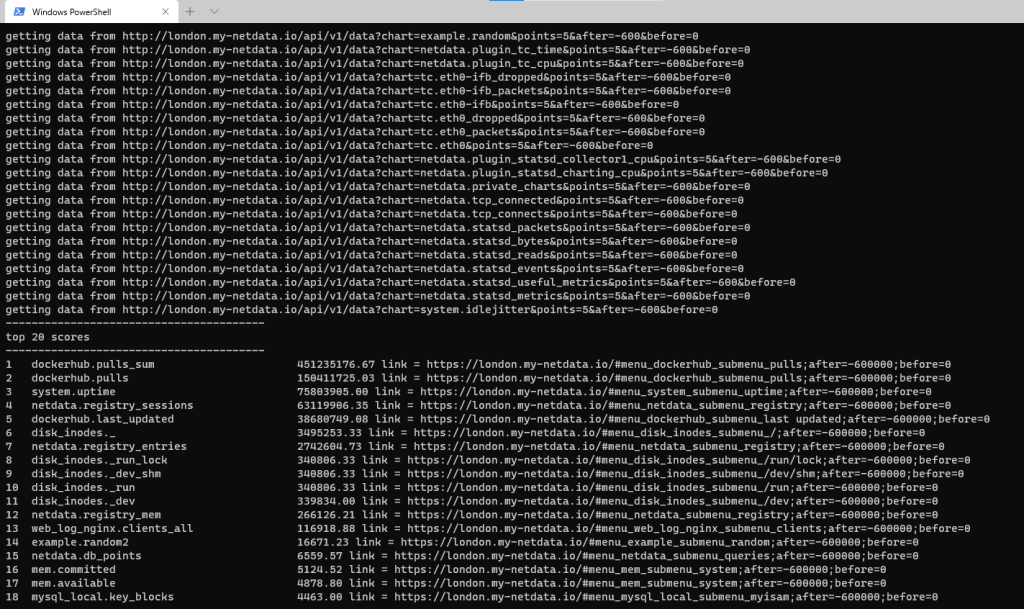
Script output
And that’s that! Got enough of a speed up for what i need and get to show my boss i used asyncio and how great i am.
Fully confident that i will be returning to this in future next time the need arises.
P.S i’d love to hear if there are better ways to do this that are sexier and more pythonic as i in no way consider myself an expert here.
Comments